This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Zheng’s “Guide to Data Structures and Algorithms” Parts 1 and Part 2 1) Big O Notation 2) Search 3) Sort 3)–i)–Quicksort 3)–ii–Mergesort 4) Stack 5) Queue 6) Array 7) Hash Table 8) Graph 9) Tree (e.g.,
However, it can be very effective when you are working with multivariate analysis and similar methods, such as Principal Component Analysis (PCA), SupportVectorMachine (SVM), K-means, Gradient Descent, Artificial Neural Networks (ANN), and K-nearestneighbors (KNN).
Some common models used are as follows: Logistic Regression – it classifies by predicting the probability of a data point belonging to a class instead of a continuous value Decision Trees – uses a tree structure to make predictions by following a series of branching decisions SupportVectorMachines (SVMs) – create a clear decision (..)
Examples include: Spam vs. Not Spam Disease Positive vs. Negative Fraudulent Transaction vs. Legitimate Transaction Popular algorithms for binary classification include Logistic Regression, SupportVectorMachines (SVM), and Decision Trees. Each instance is assigned to one of several predefined categories.
For geographical analysis, Random Forest, SupportVectorMachines (SVM), and k-nearestNeighbors (k-NN) are three excellent methods. Scalability: Verify that the algorithm can manage increasing data quantities and, if required, be applied to distributed systems. So, Who Do I Have?
SupportVectorMachines (SVM): This algorithm finds a hyperplane that best separates data points of different classes in high-dimensional space. K-NearestNeighbors (KNN): This method classifies a data point based on the majority class of its Knearestneighbors in the training data.
SupportVectorMachines (SVM) SVMs are powerful classification algorithms that work by finding the hyperplane that best separates different classes in high-dimensional space. Commonly used algorithms include SupportVectorMachines, Random Forests, and Gradient Boosting methods; however, selection should be based on testing.
We shall look at various machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. Radom Forest install.packages("randomForest")library(randomForest) 4.
SupportVectorMachine Classification and Regression C: This hyperparameter decides the regularization strength. It can have values: [‘l1’, ‘l2’, ‘elasticnet’, ‘None’]. C: This hyperparameter decides the regularization strength. The higher the value of C, the lower the regularization strength.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean?
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean?
The prediction is then done using a k-nearestneighbor method within the embedding space. Correctly predicting the tags of the questions is a very challenging problem as it involves the prediction of a large number of labels among several hundred thousand possible labels.
SupportVectorMachines (SVM) : SVM is a powerful Eager Learning algorithm used for both classification and regression tasks. Popular examples of Eager Learning algorithms include Logistic Regression, Decision Trees, Random Forests, SupportVectorMachines (SVM), and Neural Networks.
Examples include Logistic Regression, SupportVectorMachines (SVM), Decision Trees, and Artificial Neural Networks. Instead, they memorise the training data and make predictions by finding the nearest neighbour. Examples include K-NearestNeighbors (KNN) and Case-based Reasoning.
bag of words or TF-IDF vectors) and splitting the data into training and testing sets. Define the classifiers: Choose a set of classifiers that you want to use, such as supportvectormachine (SVM), k-nearestneighbors (KNN), or decision tree, and initialize their parameters.
Classification algorithms include logistic regression, k-nearestneighbors and supportvectormachines (SVMs), among others. Classification algorithms —predict categorical output variables (e.g., “junk” or “not junk”) by labeling pieces of input data.
This harmonization is particularly critical in algorithms such as k-NearestNeighbors and SupportVectorMachines, where distances dictate decisions. Scaling steps in as a guardian, harmonizing the scales and ensuring that algorithms treat each feature fairly.
This type of machine learning is useful in known outlier detection but is not capable of discovering unknown anomalies or predicting future issues. Isolation forest models can be found on the free machine learning library for Python, scikit-learn.
Logistic Regression K-NearestNeighbors (K-NN) SupportVectorMachine (SVM) Kernel SVM Naive Bayes Decision Tree Classification Random Forest Classification I will not go too deep about these algorithms in this article, but it’s worth it for you to do it yourself.
For larger datasets, more complex algorithms such as Random Forest, SupportVectorMachines (SVM), or Neural Networks may be more suitable. In contrast, for datasets with low dimensionality, simpler algorithms such as Naive Bayes or K-NearestNeighbors may be sufficient.
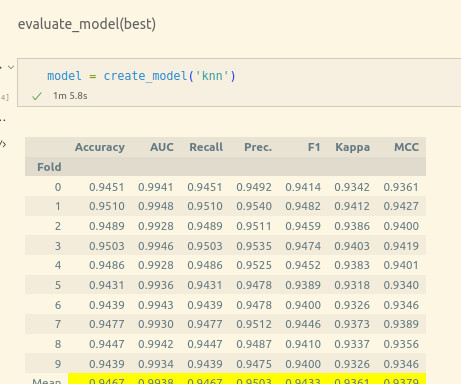
With the preprocessed data in hand, we can now employ pyCaret, a powerful machine learning library, to build our predictive models. pyCaret simplifies the machine learning pipeline by automating various steps, such as feature selection, model training, hyperparameter tuning, and model evaluation.
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. To make this work, we need to transform the textual interactions into a format that allows algebraic operations.
Supervised Anomaly Detection: SupportVectorMachines (SVM): In a supervised context, SVM is trained to find a hyperplane that best separates normal instances from anomalies. k-NearestNeighbors (k-NN): In the supervised approach, k-NN assigns labels to instances based on their k-nearest neighbours.
K-NearestNeighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance. A smaller k implies the model is influenced by a limited number of neighbours, causing predictions to be more sensitive to noise in the training data.
Every Machine Learning algorithm, whether a decision tree, supportvectormachine, or deep neural network, inherently favours certain solutions over others. k-NearestNeighbors (k-NN) The k-NN algorithm assumes that similar data points are close to each other in feature space.
spam detection), you might choose algorithms like Logistic Regression , Decision Trees, or SupportVectorMachines. customer segmentation), clustering algorithms like K-means or hierarchical clustering might be appropriate. K-NearestNeighbors), while others can handle large datasets efficiently (e.g.,
K-Nearest Neighbou r: The k-NearestNeighbor algorithm has a simple concept behind it. The method seeks the knearest neighbours among the training documents to classify a new document and uses the categories of the knearest neighbours to weight the category candidates [3].
KK-Means Clustering: An unsupervised learning algorithm that partitions data into K distinct clusters based on feature similarity. K-NearestNeighbors (KNN): A simple, non-parametric classification algorithm that assigns a class to a data point based on the majority class of its Knearest neighbours.
For example, in fraud detection, SVM (supportvectormachine) can classify transactions as fraudulent or non-fraudulent based on historically labeled data. For example, The K-NearestNeighbors algorithm can identify unusual login attempts based on the distance to typical login patterns.
Trade-off Of Bias And Variance: So, as we know that bias and variance, both are errors in machine learning models, it is very essential that any machine learning model has low variance as well as a low bias so that it can achieve good performance. Another example can be the algorithm of a supportvectormachine.
They are: Based on shallow, simple, and interpretable machine learning models like supportvectormachines (SVMs), decision trees, or k-nearestneighbors (kNN). Traditional Active Learning has the following characteristics. Works well with small datasets and models with fewer parameters.
among supervised models and k-nearestneighbors, DBSCAN, etc., Feel free to try other algorithms such as Random Forests, Decision Trees, Neural Networks, etc., among unsupervised models.
Hybrid machine learning techniques integrate clinical, genetic, lifestyle, and omics data to provide a comprehensive view of patient health ( Image credit ) The choice of an appropriate model is critical in predictive modeling. Hybrid machine learning techniques excel in model selection by amalgamating the strengths of multiple models.
Specific types of machine learning algorithms Among the several algorithms available, some notable types include: Supportvectormachine (SVM): Ideal for binary classification tasks. K-nearestneighbors (KNN): Classifies based on proximity to other data points.
SupportVectorMachines (SVM) : A good choice when the boundaries between file formats, i.e. decision surfaces, need to be defined on the basis of byte frequency. K-NearestNeighbors (KNN) : For small datasets, this can be a simple but effective way to identify file formats based on the similarity of their nearestneighbors.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content