This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SupportVectorMachines (SVMs) are powerful for solving regression and classification problems. You should have this approach in your machinelearning arsenal, and this article provides all the mathematics you need to know -- it's not as hard you might think.
Introduction Supportvectormachines are one of the most widely used machinelearning algorithms known for their accuracy and excellent performance on any dataset.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article, we will be discussing SupportVectorMachines. The post SupportVectorMachine: Introduction appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction to SupportVectorMachine(SVM) SVM is a powerful supervised algorithm that works best on smaller datasets but on complex ones. The post SupportVectorMachine(SVM): A Complete guide for beginners appeared first on Analytics Vidhya.
Hinge loss is pivotal in classification tasks and widely used in SupportVectorMachines (SVMs), quantifies errors by penalizing predictions near or across decision boundaries. By promoting robust margins between classes, it enhances model generalization. appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction SupportVectorMachine (SVM) is one of the MachineLearning. The post The A-Z guide to SupportVectorMachine appeared first on Analytics Vidhya.
The SupportVectorMachine algorithm is one of the most popular supervised machinelearning techniques, and it comes implemented in the OpenCV library. This tutorial will introduce the necessary skills to start using SupportVectorMachines in OpenCV, using a custom dataset that we will generate.
The post Understanding Naïve Bayes and SupportVectorMachine and their implementation in Python appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Introduction In this digital world, spam is the most troublesome challenge that.
Ever wondered, how great would it be, if we could predict, whether our request for a loan, will be approved or not, simply by the use of machinelearning, from the ease and comfort […]. The post Loan Status Prediction using SupportVectorMachine (SVM) Algorithm appeared first on Analytics Vidhya.
Unlocking a New World with the SupportVector Regression Algorithm SupportVectorMachines (SVM) are popularly and widely used for classification problems in machine. The post SupportVector Regression Tutorial for MachineLearning appeared first on Analytics Vidhya.
Supportvectormachines (SVM) are at the forefront of machinelearning techniques used for both classification and regression tasks. What are supportvectormachines (SVMs)? Advantages of supportvectormachines SVMs offer several advantages, particularly in terms of accuracy and efficiency.
Introduction One of the classifiers that we come across while learning about. The post The Mathematics Behind SupportVectorMachine Algorithm (SVM) appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction A SupportVectorMachine (SVM) is a very powerful and. The post SupportVectorMachine and Principal Component Analysis Tutorial for Beginners appeared first on Analytics Vidhya.
ArticleVideo Book Objective Learn how the supportvectormachine works Understand the role and types of kernel functions used in an SVM. The post Beginner’s Guide to SupportVectorMachine(SVM) appeared first on Analytics Vidhya. Introduction.
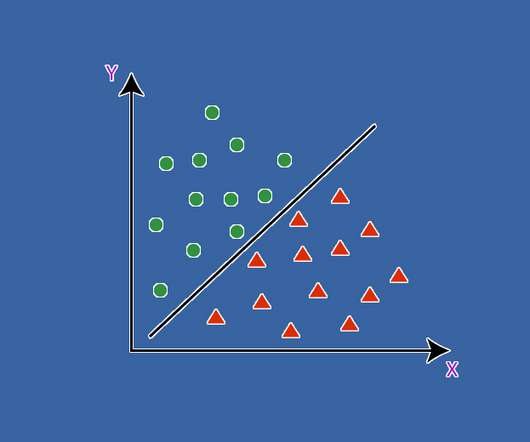
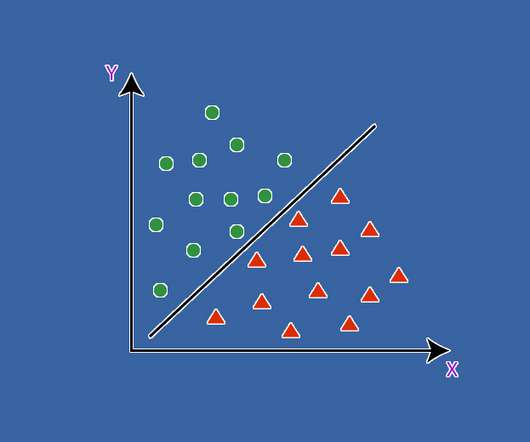
This post focuses on building an intuition of the SupportVectorMachine algorithm in a classification context and an in-depth understanding of how that graphical intuition can be mathematically represented in the form of a loss function. We will also discuss kernel tricks and a more useful variant of SVM with a soft margin.
SupportVectorMachines (SVM) are a cornerstone of machinelearning, providing powerful techniques for classifying and predicting outcomes in complex datasets. What are SupportVectorMachines (SVM)? They work by identifying a hyperplane that best separates distinct classes within the data.
The post Introduction to SVM(SupportVectorMachine) Along with Python Code appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction This article aims to provide a basic understanding.
Machinelearning practices are the guiding principles that transform raw data into powerful insights. By following best practices in algorithm selection, data preprocessing, model evaluation, and deployment, we unlock the true potential of machinelearning and pave the way for innovation and success.
In a previous tutorial, we have explored the use of the SupportVectorMachine algorithm as one of the most popular supervised machinelearning techniques that comes implemented in the OpenCV library.
Introduction Supportvectormachine is one of the most famous and decorated machinelearning algorithms in classification problems. This article was published as a part of the Data Science Blogathon.
By understanding machinelearning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Predict traffic jams by learning patterns in historical traffic data. Learn in detail about machinelearning algorithms 2.
There are dozens of machinelearning algorithms out there. It is impossible to learn all their mechanics; however, many algorithms sprout from the most established algorithms, e.g. ordinary least squares, gradient boosting, supportvectormachines, tree-based algorithms and neural networks.
Introduction The One-Class SupportVectorMachine (SVM) is a variant of the traditional SVM. It is specifically tailored to detect anomalies. Its primary aim is to locate instances that notably deviate from the standard.
Summary: Classifier in MachineLearning involves categorizing data into predefined classes using algorithms like Logistic Regression and Decision Trees. Introduction MachineLearning has revolutionized how we process and analyse data, enabling systems to learn patterns and make predictions.
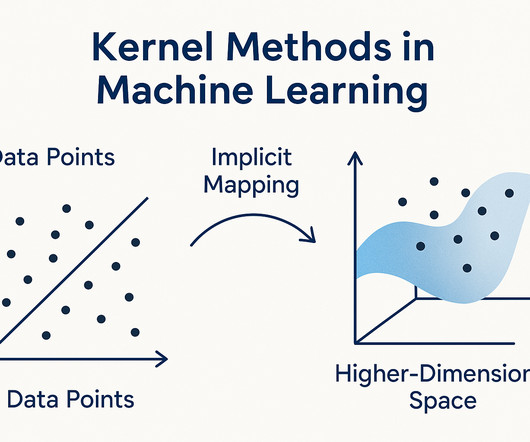
Summary: Kernel methods in machinelearning solve complex data problems using smart functions like the kernel trick. Learn how they work and how to apply them in real-world projects through Pickl.AIs data science courses. Learn how they work and how to apply them in real-world projects through Pickl.AIs data science courses.
Summary: MachineLearning algorithms enable systems to learn from data and improve over time. Introduction MachineLearning algorithms are transforming the way we interact with technology, making it possible for systems to learn from data and improve over time without explicit programming.
10 Python packages for data science and machinelearning In this article, we will highlight some of the top Python packages for data science that aspiring and practicing data scientists should consider adding to their toolbox. Scikit-learn Scikit-learn is a powerful library for machinelearning in Python.
Among the most significant models are non-linear models, supportvectormachines, and linear regression. Supportvectormachines (SVM) SupportVectorMachines are a robust classification technique in machinelearning.
Classification in machinelearning involves the intriguing process of assigning labels to new data based on patterns learned from training examples. Machinelearning models have already started to take up a lot of space in our lives, even if we are not consciously aware of it. 0 or 1, yes or no, etc.).
These features can be used to improve the performance of MachineLearning Algorithms. In the world of data science and machinelearning, feature transformation plays a crucial role in achieving accurate and reliable results.
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machinelearning, involving algorithms that create new content on their own. This approach involves techniques where the machinelearns from massive amounts of data.
R has become ideal for GIS, especially for GIS machinelearning as it has topnotch libraries that can perform geospatial computation. R has simplified the most complex task of geospatial machinelearning and data science. Author(s): Stephen Chege-Tierra Insights Originally published on Towards AI. data = trainData) 5.
Rustic Learning: MachineLearning in Rust — Part 2: Regression and Classification An Introduction to Rust’s MachineLearning crates Photo by Malik Skydsgaard on Unsplash Rustic Learning is a series of articles that explores the use of Rust programming language for machinelearning tasks.
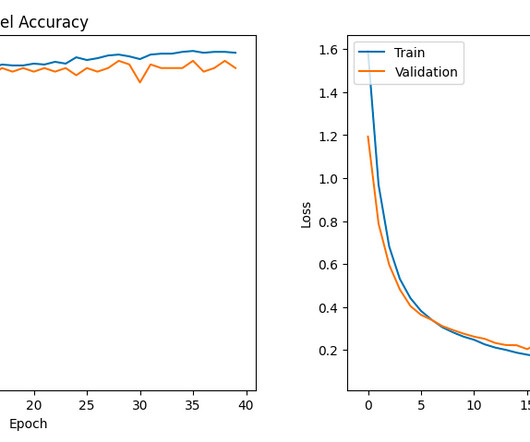
Introduction Assessing a machinelearning model isn’t just the final step—it’s the keystone of success. Imagine building a cutting-edge model that dazzles with high accuracy, only to find it crumbles under real-world pressure.
They are also used in machinelearning, such as supportvectormachines and k-means clustering. Robust inference: Robust inference is a technique that is used to make inferences that are not sensitive to outliers or extreme observations.
Common types of surrogate models Surrogate modeling encompasses various machinelearning methodologies, including: Polynomial regressions: Useful for capturing relationships in a straightforward manner. Supportvectormachines: Effective in high-dimensional spaces and can handle nonlinearities.
Understanding the Principles, Challenges, and Applications of Gradient Descent Image by Author with @MidJourney Introduction to Gradient Descent Gradient descent is a fundamental optimization algorithm used in machinelearning and data science to find the optimal values of the parameters in a model.
This method aids in finding the optimal solution of a problem, making it essential for applications ranging from machinelearning to finance. The importance of this discipline becomes clear when considering the vast range of optimization issues faced in industries like finance, engineering, and machinelearning.
Beginner’s Guide to ML-001: Introducing the Wonderful World of MachineLearning: An Introduction Everyone is using mobile or web applications which are based on one or other machinelearning algorithms. You might be using machinelearning algorithms from everything you see on OTT or everything you shop online.
Machinelearning is playing a very important role in improving the functionality of task management applications. However, recent advances in applying transfer learning to NLP allows us to train a custom language model in a matter of minutes on a modest GPU, using relatively small datasets,” writes author Euan Wielewski.
The competition for best algorithms can be just as intense in machinelearning and spatial analysis, but it is based more objectively on data, performance, and particular use cases. For geographical analysis, Random Forest, SupportVectorMachines (SVM), and k-nearest Neighbors (k-NN) are three excellent methods.
For example, we have seen instances throughout the history of machinelearning where researchers have argued for fixing an architecture and using it for short-term success, ignoring potential for long-term disruption. This encourages us to think beyond simply improving the existing system.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content